I know that it seems like many of you have been waiting a long time for this but…we’re happy to announce that Office365Mon is now offering monitoring for Microsoft Teams! We have just released a couple of new monitoring options for Microsoft Teams into Preview mode at Office365Mon.Com. Our support is launching with two specific functional areas of Teams we’re monitoring – 1) the overarching Teams service, and 2) the Channels feature of Microsoft Teams, which is one of the core pillars of the platform.
To do this we’re starting with two new features, which we call Microsoft Teams Monitoring, and Microsoft Teams Advanced Monitoring. Over time, as Microsoft adds new features to the Microsoft Teams service, we’ll roll those into our Teams monitoring packages so you can stay on top of them. As with all the other features at Office365Mon, our goal is to make the setup and management for monitoring Microsoft teams as easy and painless as possible. To get started, you’ll just go into our Configure Office365Mon page at https:// office365mon.com/Signup/Status, scroll down and then simply click on the Enable button in the Microsoft Teams Info section of the page. That’s it – that’s all you need to do to get started. Just like we do with other Office 365 services that we monitor – like SharePoint, Exchange, and OneDrive – we also give you the flexibility to focus in on a specific resource for monitoring purposes. So we’ll go out and get a list of all the Microsoft Teams you are joined to, and then you can pick which one you want to use as we start monitoring it.
We also simplify the process of configuring monitoring, in that you don’t have to go pick which Teams, and Channels to monitor – just clicking the Enable button is enough to get you started. After that, if you have both Microsoft Teams monitoring features, then we’ll monitor both Teams and Channels; if you only have one, then we’ll just monitor Teams. We figure that out for you so you don’t have to hassle with it.
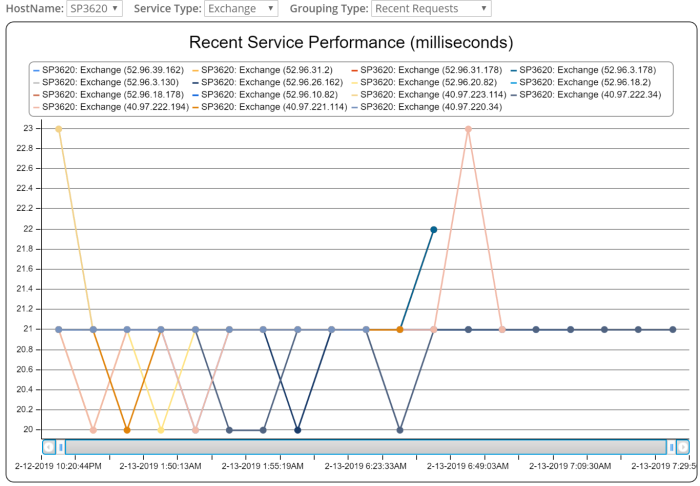
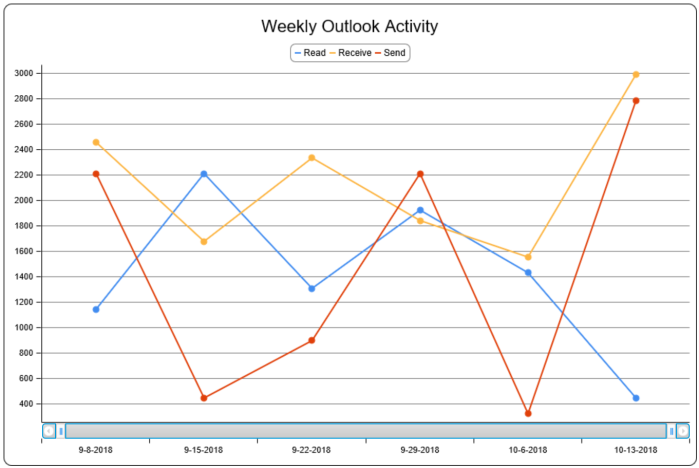
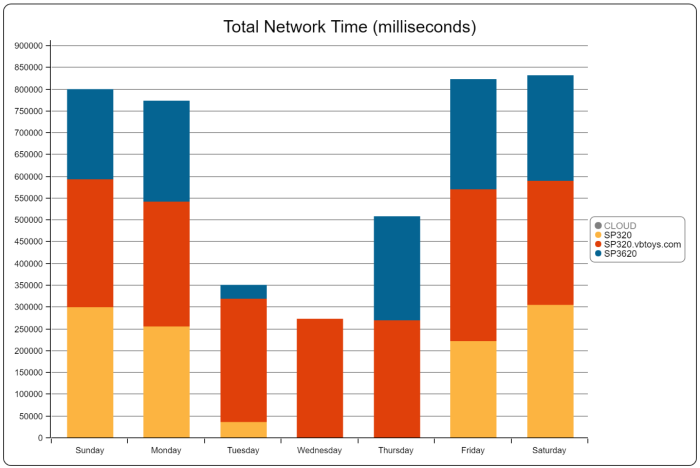
From a reporting standpoint, Microsoft Teams data then begins to automatically show up in reports, just like any other Office 365 resources. So you don’t need to go find special reports just for Microsoft Teams, because the Teams monitoring data shows up with all of the reports you already know and love. We’re also able to do more in-depth analysis of your Microsoft Teams performance as well, meaning as we look at the performance for your Teams tenant, we can break down where time is spent in processing requests. Is it happening in your tenant itself, so there is slowness in the cloud? Or is there perhaps a performance issue on your network as your users utilize the Teams feature sets. Here’s a quick look at one of the reports from our Distributed Probes and Diagnostics agent – it ALSO now includes support for Microsoft Teams so you can see what the Teams performance is like across all of the different geographic locations where you have users:

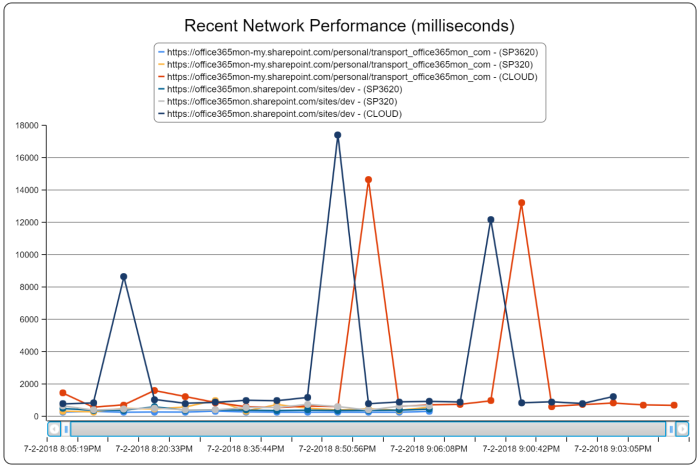
You’ll also see data from Teams now integrated into our Tenant Performance and Health reports. This is one that we’ve recently updated so that it shows you not only the tenant-level performance of the recent health probes that have been issued, but it also has an underlay that displays the historical data for the same point in time as when you are viewing the report. So if you’re looking at the report at 2PM on a Thursday, then you’ll see historically what the performance has been like at 2PM on a Thursday so you know if your current performance is in line with what you normally see, or if you’ve hit a performance issue in your tenant. Here’s an example of that:

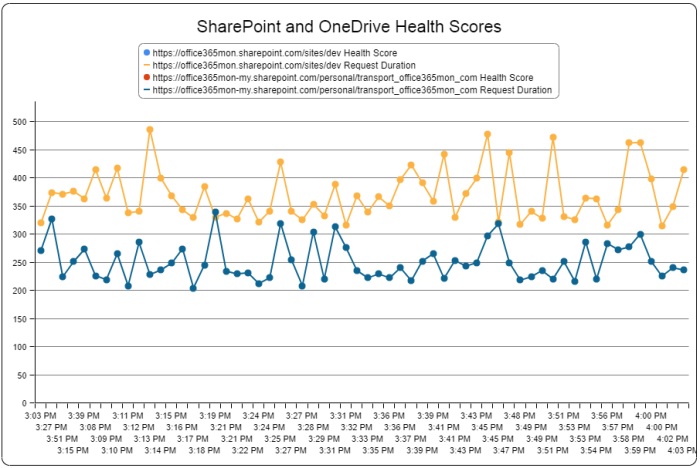
Also, just like many of the other services we monitor, you can also compare what the overall performance is like for your Teams tenant versus all other Office365Mon customers that are monitoring Microsoft Teams. Here’s what that looks like:

Start Monitoring Teams Today
As we do every time we release a new feature, we’ve enabled Microsoft Teams and Teams Channel monitoring for all existing Office365Mon customers. You just need to go to the Configure Office365Mon page at https://www.office365mon.com/Signup/Status and click the Enable button in the Microsoft Teams Info section. Once you do that, you’ll be able to see Teams performance data begin to show up in the reports mentioned above along with several others. You’ll also get notifications when we detect an outage with your Microsoft Teams service.
For new customers, we turn on Microsoft Teams monitoring along with all of our other features for free for 90 days when you create a trial subscription. Just visit our site at https://office365mon.com and click on the big Start Now link on the home page. We don’t require any payment information up front, so you can be up and running in about two minutes to monitor Office 365.
As I always say, if you have feedback on this feature or any other feature you would like to see, please do not hesitate to contact me. You can always email us at support@office365mon.com, and be assured that I read each and every feature feedback and suggestion we get through there.
I hope you’ll find our new Microsoft Teams monitoring features to be a welcome addition to the wide array of monitoring services we offer here at Office365Mon.Com.
From Sunny Phoenix,
Steve